重要な文書をスムーズに処理
あらゆるフォーマットの文書コンテンツを自動的に抽出し、処理します。これにより、手作業による手間が大幅に削減されます。
ABBYY FlexiCapture


ABBYY FlexiCapture は、単なるインテリジェントなデータキャプチャ・抽出ソリューションではなく、最高水準の人工知能(AI)、自然言語処理(NLP)、機械学習(ML)、高度な認識(AI OCR)機能を1つの企業規模の文書自動化プラットフォームに統合し、ビジネス文書からすべてのデータを変換してくれるソリューションなのです。
FlexiCaptureは、企業が文書処理を自動化するためのソリューションです。グローバル企業はより迅速な電子申請処理、タッチレス処理、コスト削減、プロセスの可視化を実現することができます。フォーマットや言語、サーバー、ステーション、仮想環境といったFlexiCaptureの仕様については詳細をご覧ください。
企業内の文書自動化は、目的に特化された総合的なAIプラットフォームから始まります。このプラットフォームは、正しい情報の取得、処理、検証を行い、重要な作業プロセスですぐに使える状態にします。
効率アップ
の軽減
(デジタル・トランスフォーメーション)の実現


深層学習を活用した最新の文書分類技術を使用することで、運転免許証、銀行取引明細書、契約書、請求書などの様々な文書を効果的に分類できます。さらに、テキストの内容や画像パターンに基づいて、カスタムのサブカテゴリ(例:業者Aからの請求書、業者Bからの請求書など)も作成できます。これにより、効率的な分類がされ高度な文書管理が可能になります。
文書画像は、複数ページのドキュメントとしてまとめられます。

文書の内容とデータは、自動的に抽出、検証されます。FlexiCaptureは、高精度のOCR/ICR/OMRおよびバーコード認識を使用しています。また、データベースとの比較や組み込まれた検証ルールに従い自動検証をおこないます。
検証ステーションでは、抽出されたフィールドが元の文書のフィールドと一致するかどうかをチェックすることができます。

ABBYY FlexiCaptureの製品提供状況、技術、アーキテクチャ、およびカスタマイズ可能な機能について詳細を学びましょう。
FlexiCaptureを使用すると、特定の社内またはアウトソーシングされたビジネスシナリオの要件を満たすアプリケーションを簡単に作成できます。FlexiCaptureのカスタマイズスクリプトとWebサービスAPIにより、企業は特定のニーズに合わせて処理段階やデータルーティングをカスタマイズできます。


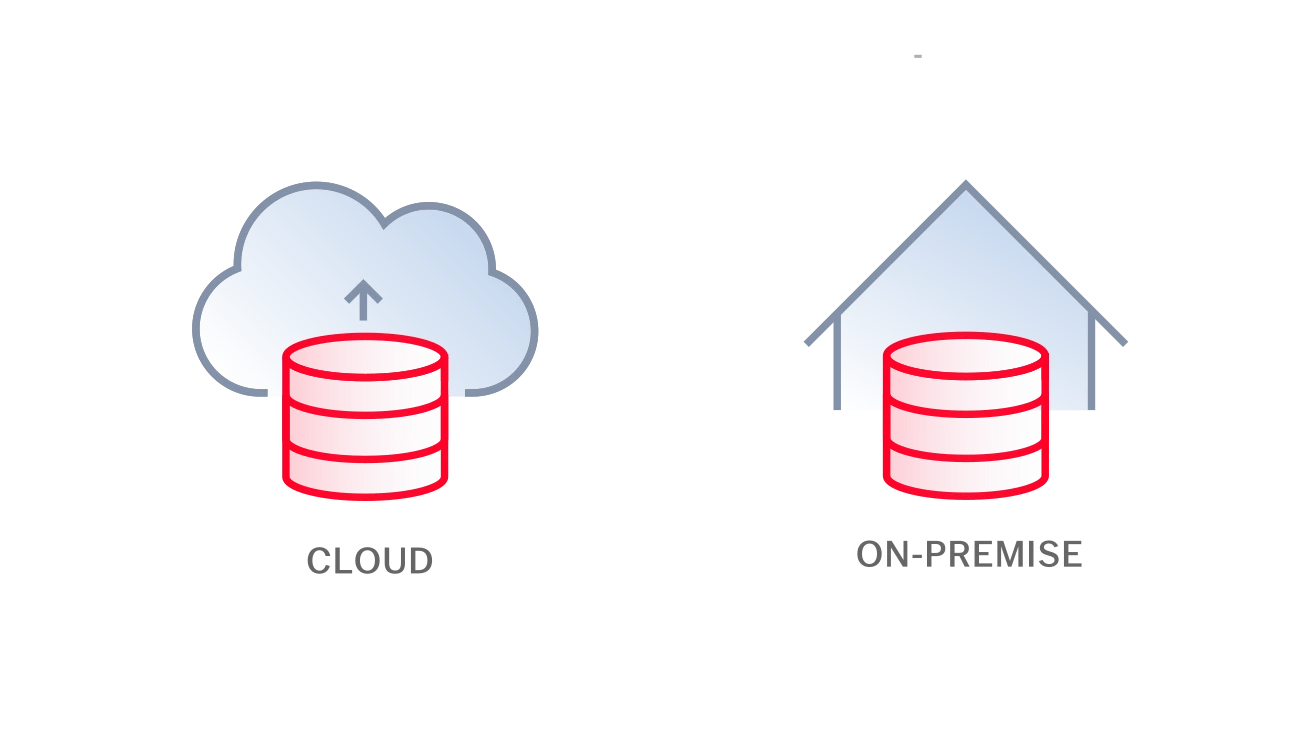
FlexiCaptureは、お客様の環境に最適な形で導入できます。 そして、FlexiCaptureの構成は、オンプレミス、クラウドのどちらにも対応しています。用途に応じて、いずれかを選択しての導入が可能です。
ABBYY FlexiCapture Cloudは、クラウドネイティブなセキュリティ機能を備えています。これらは、インフラストラクチャとプラットフォームレイヤーのいずれにも関連しています。この製品は、SOC2 Type 1によって認証されており、TSP Section 100の基準に従って安全性と機密性が設計されています。2017年版の安全性、可用性、プロセスの規範、機密性およびプライバシーのためのTrustサービス原則(2017 Trust Services Criteria for Security, Availability, Processing Integrity, Confidentiality:AICPA)、および Trustサービス原則(Trust Services Criteria)を満たしています。 監査報告書は、PricewaterhouseCoopers Germanyによって作成されました。
ABBYY FlexiCapture Cloudに搭載されたREST APIを使用して、システム統合を行うことができます。REST API は、文書のアップロードやデータ抽出の結果を外部システムが受け取れるようにサポートします。また、抽出結果に関してのフィードバックを与えることにより、FlexiCaptureに学習させ、各ユーザー独自の検証も可能となります。
ABBYYのインテリジェントオートメーションのデモンストレーションを予約して、貴社の業務効率化やコスト削減、顧客サービスの向上など、さまざまな課題を解決する方法をご覧ください。