Blog
Artificial Intelligence Solutions for Document Classification
Automatically sort and organize your unstructured content with AI to improve efficiency, compliance, and search capabilities.

Document classification and splitting


Document classification automatically identifies and organizes your documents, sorting them by type based on their content and context. Once classified correctly within the intelligent document processing platform, documents can be automatically routed to the correct extraction models, purpose-built for accurate and efficient data extraction from a particular document type.
Easily create and train document classification models tailored to your specific business needs. Simply provide a few examples of each document type—such as bills of lading, claims forms, invoices, or CVs—and the model will quickly learn to recognize and sort them accurately. ABBYY’s low-code platform makes this process intuitive and straightforward, so you can deploy document classification quickly even with minimal technical expertise.

Document classification streamlines the sorting of business documents, saving valuable time and resources. ABBYY’s purpose-built AI uses advanced technologies like machine learning and natural language processing (NLP) to read all your documents—be they structured forms like IDs, semi-structured formats like utility bills, or unstructured documents like contracts—and make sense of all kinds of data.
Select the categories that you want to sort your documents into. For instance, you might want to put invoices, contracts, and resumes into separate classes so they can be routed to different workflows.
If a file contains multiple documents, document splitting models separate them into individual documents. This way, even large or complex files are handled correctly.
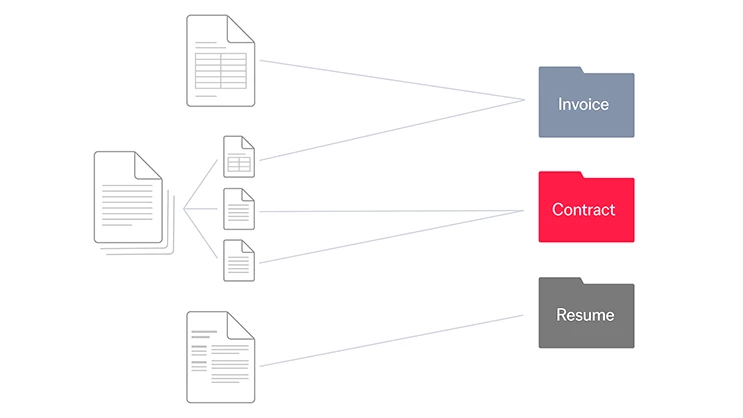
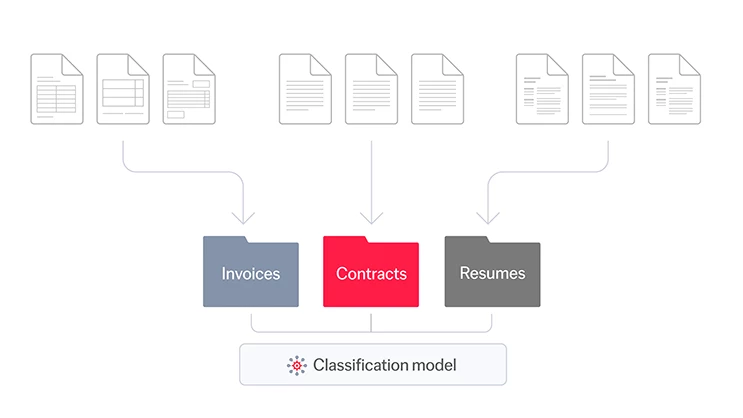
Once the classes are defined, you provide a set of example documents for each class. These examples serve as training data for the AI algorithms, which learn how to distinguish document classes by specific features of their layouts and textual content. With this knowledge, the AI can identify incoming information with precision.
Fine-tuning the classification model is a crucial part of this training process to make sure all relevant documents are accounted for, while avoiding mistakes.
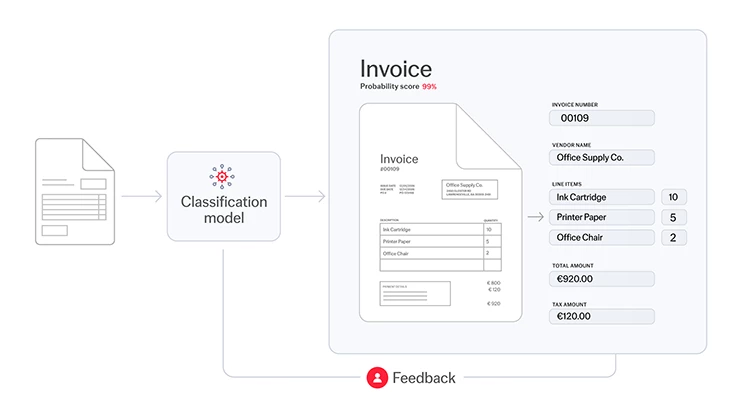
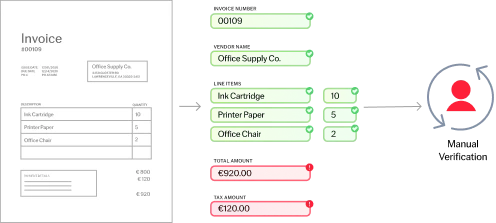
Now, your classification model is trained and ready for use. Every new document that enters your system gets analyzed by the model to determine the type of content it is. Each item also gets a probability score that lets you know how confident the model is about its choice.
Once the document is identified, it gets sorted and routed to the right data extraction model designed to pull specific data—such as ID numbers, shipping dates, or beneficiary names—from that document. All the while, your classification model keeps on learning and improving its accuracy through a human-in-the-loop process. The feedback from these manual checks helps the model get smarter over time, leading to more precise automation and less need for human intervention.
Ingest documents from multiple channels—mobile devices, email, shared folders, network scanners, and direct connections to business systems via API or pre-built connectors—ensuring seamless integration into your workflows, no matter how documents enter your organization. This flexibility empowers you to efficiently support diverse business processes, adapting to your specific needs and streamlining operations from every entry point.
The quality of document images can vary significantly due to issues like poor lighting and distortions from mobile cameras—or come with multiple auxiliary elements such as patterned backgrounds, protection marks, field markings, lines, and guides that obscure important information.
ABBYY’s AI-powered image enhancement algorithms optimize each image for accurate data extraction. The AI corrects distortions and separates text from the background, cleaning up even the most complex and visually busy documents—such as IDs, birth certificates, and forms—to achieve reliable results and high straight-through processing rates.
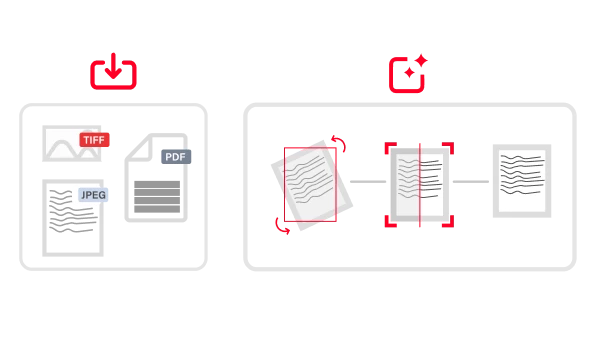
AI has transformed the ability to read and interpret content previously deemed impossible to process, dramatically expanding the use cases for automation. ABBYY IDP uses advanced AI-based optical character recognition (OCR) and intelligent character recognition (ICR) technologies to digitize printed and handwritten text, preparing it for further processing. These technologies are able to recognize the logical structure of the whole document, including complex elements such as tables, enabling document classification, data extraction, and high-quality export to digital formats.
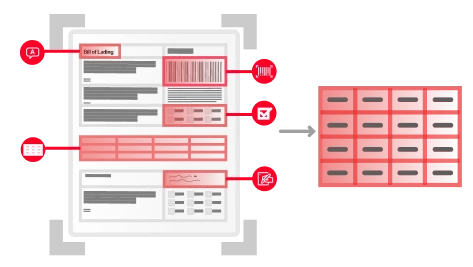
Automate document classification and routing with AI classification models that analyze both text and image features through multimodal learning to recognize and organize documents. Once classified, documents are automatically assigned an AI extraction model for processing. By incorporating human-in-the-loop input, the models learn from user corrections and automatically adjust, continuously improving their performance over time.
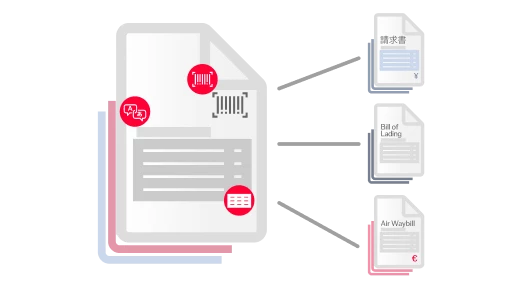
Extract data from structured, semi-structured, or unstructured business documents using advanced AI and machine learning that mimic human understanding. ABBYY IDP reads and understands documents in over 200 languages and effortlessly handles complex tables, handwriting, checkmarks, barcodes, signatures, and more.
Automatic validation cross-checks information against databases and ensures compliance with built-in validation rules. Our low-code design approach gives you the flexibility to use pre-trained models available in the ABBYY Marketplace, tweak these ready-to-use models for the unique needs of your organization, or train custom models tailored to your specific documents.
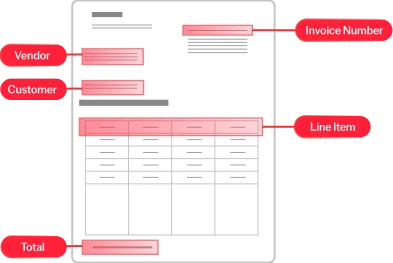
Keep refining your processes through human-in-the-loop (HITL) review, which lets subject matter experts step in to manually check and correct document classes as well as extracted data through a convenient interface. This optional step is crucial when 100% accuracy is required or when a document doesn’t meet the specific validation rules established for each AI model. Each time a correction is made, the AI models improve through continuous learning and get more accurate.
The advanced quality analytics provided by ABBYY Document AI provide a clear understanding of your document processing performance and track improvements in straight-through processing rates over time. With actionable insights and tailored recommendations, you can pinpoint the root causes of problems and take effective actions to improve data extraction quality of the models for superior business outcomes within your IDP workflow.

ABBYY Document AI automatically exports data in the required format to meet your needs—whether JSON, CSV, XML, or others. The data is then sent seamlessly to your automation systems and business applications through simple REST API or pre-built connectors into your downstream processes.
Automatically sort and organize your unstructured content with AI to improve efficiency, compliance, and search capabilities.
Find out how AI tackles complex documents and boosts efficiency, freeing up your finance team for strategic work.
Overcome supply chain disruptions and unleash efficiency with AI-powered document processing.
Automatically sort and organize your unstructured content with AI to improve efficiency, compliance, and search capabilities.
Find out how AI tackles complex documents and boosts efficiency, freeing up your finance team for strategic work.
Overcome supply chain disruptions and unleash efficiency with AI-powered document processing.
Automatically sort and organize your unstructured content with AI to improve efficiency, compliance, and search capabilities.
Find out how AI tackles complex documents and boosts efficiency, freeing up your finance team for strategic work.
Overcome supply chain disruptions and unleash efficiency with AI-powered document processing.
Document classification is the process of automatically categorizing business documents precisely and quickly, using automation to reduce errors, save time, and optimize resources.
Traditionally, figuring out what a document was and where it should go involved a lot of hands-on effort, complex programming, or both. A person, typically trained with industry-specific expertise, was required to read each email or navigate through every legal document. Today, powerful AI tools have changed the game entirely. Instead of having a professional look at each document to decide what to do with it, you can now leverage machine learning and advanced algorithms to streamline the entire process.
Here’s how that process goes: Every document that comes into your business is scanned by AI tools and analyzed, so that it can be sorted into predetermined categories. Once sorted, your organized documents can be routed to the right place for efficient processing, data extraction, or further action.
Yes. You can customize document classification tools for your unique business needs by creating tailored classification models or "skills" that define how specific documents should be identified and processed.
Training these skills is remarkably simple. Just provide a few example files for each category you want to identify, then let AI tools analyze these examples, learning to distinguish between different document types based on their visual layout, text content, and subtle details like seals or signatures.
Once trained, your custom skills can be seamlessly integrated into your workflows. Incoming documents are sorted and routed based on their identified type. This flexibility allows you to optimize document handling, whether you're dealing with structured forms, semi-structured invoices, or unstructured correspondence.
The best document classification tools are designed with simplicity in mind, offering an intuitive, low-code/no-code interface that lets you create and train custom classification models without extensive programming knowledge. Simply provide a few examples of each class and assign the correct labels or tags to help the system learn how to identify and classify similar documents in the future.
Schedule a demo and see how ABBYY intelligent automation can transform the way you work—forever.