Difference between ETL and ELT
Andrew Pery
October 8, 2024
Early advancements in the modern computer era laid the foundation for data integration. In the 1970s, the “extract, transform, and load” methodology, commonly referred to as “ETL,” pioneered a standardized technique for facilitating data integration. It became more prominent for enabling businesses to collect and transform data, before loading it into target data warehouses for analysis.
Decades later, cloud computing's emergence in the 2000s brought about the rise of cloud data lakes and data warehouses. This led to the introduction of ELT, a more flexible and scalable approach to data transformation that built upon ETL’s capabilities. Today, ELT enables businesses to send data directly to a data warehouse, where it's transformed just before analysis.
In this article, we’ll explain exactly what ETL and ELT processes involve, the differences between them, and how choosing the right data transformation will impact your business processes.
Jump to:
What is ETL?What is ELT?
ETL vs ELT: What’s the difference?
Comparison of ETL and ELT
ETL vs ELT: What are the similarities?
When to use ETL vs. ELT
Which is right for you: ETL or ELT?
What is ETL?
Extract, transform, and load (ETL) is a data integration methodology used to transform data from multiple systems and applications for analysis. This process involves normalization, cleansing, deduplication, and formatting during the data transformation phase, before the data is moved to a data warehouse for further analysi s.
To facilitate meaningful analysis, the transformation of source data is essential, and traditionally requires specialist IT skills with SQL or NoSQL, scripting, and data mapping. ETL is particularly beneficial for organizations that need to analyze structured data with online analytical processing (OLAP) tools.
The ETL process happens in three steps:
- Extract raw data from relevant sources
- Use a secondary processing server to transform the data
- Load the data into a target database
What is ELT?
Extract, load, and transform (ELT) enables you to transfer raw data directly into a data warehouse or data lake, where it can be cleaned, transformed, and enriched, bypassing the need for pre-processing. ELT differs from ETL by directly loading raw data into a target data warehouse without the need for a secondary server, which streamlines the loading process. This process builds on the capabilities of ETL by leveraging the power and scalability of a cloud data warehouse’s infrastructure. Data warehouses also often store raw data indefinitely, which gives you the flexibility to interact with and transform your raw data multiple times.
The three key steps in the ELT process are:
- Extract raw data from relevant sources
- Load data into a data warehouse or data lake in its raw state
- Transform the data as required within the target system
ETL vs ELT: What’s the difference?
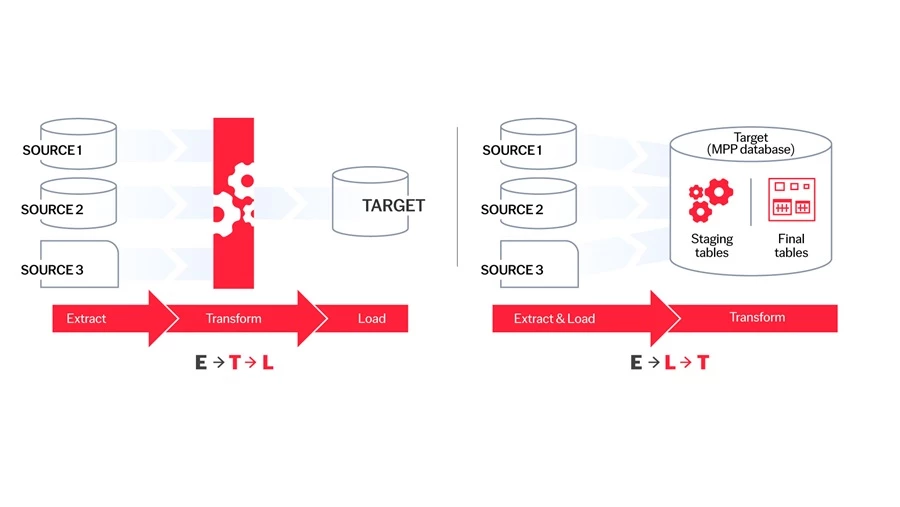
Some organizations use both ETL and ELT in their processes to address all their data pipeline requirements comprehensively. But, if you’re considering which of the two processes will best suit your business needs, we’ve broken down the differences to help you choose.
Process
In the ETL process, raw data is extracted from various sources, and this data is transformed into a predetermined format using a secondary processing server. The final stage of the process is to load the completed data into the target database.
On the other hand, with ELT, raw data is extracted and then loaded directly into the target data warehouse. You can then transform the data as needed.
Data volume
ETL is most suitable for processing smaller data sets that require complex transformations and have a predefined purpose for meeting analysis objectives. In comparison, the critical value of ELT lies in its ability to transform very large volumes of data quickly, including real-time streaming, leveraging the power and scalability of the cloud infrastructure.
Data compatibility
ETL is best suited for processing structured data that you can represent in tables. It transforms one set of structured data into another structured format, and then loads it into the target database.
In comparison, ELT is capable of handling all data types, including unstructured data like images, and making it accessible to business intelligence systems. During the ELT process, the different data formats are loaded into the target data warehouse, where you can transform them into your desired format.
Speed
The ETL process involves transforming data through a processing server, before it can be loaded into the target data warehouse. This can slow workflows down, especially with larger datasets.
ELT stands out as the faster, more efficient choice, especially in terms of data availability and load times. ELT accelerates data integration by loading data without the need for transformation first, empowering users to only identify and analyze the specific data they require.
Costs
ETL is a detailed process that comes with a number of costs. Analysts have to pre-plan reports before data transformation to define how data should be structured and formatted. Maintaining multiple servers can also present cost issues, making it a less attainable option for small and medium businesses.
In comparison, ELT is typically carried out within a simplified data stack, because all transformations take place in the data warehouse. With fewer systems required to carry out the process, ELT comes with less maintenance and lower setup costs. Additionally, cloud-based options offer more flexible plans for data storage and processing.
Security
When handling personal data, it's crucial for organizations to comply with data privacy regulations to protect personally identifiable information (PII).
ETL supports data privacy and compliance efforts by requiring users to transform and cleanse sensitive data before loading it into the data warehouse. Developers have to manually create tailored rules before the loading stage to monitor and protect their data.
In comparison, ELT solutions offer a range of built-in security features, such as multi-factor authentication, which are integrated directly into the data warehouse to protect transferred data. This allows you to focus on analytics, reducing time spent on data regulation and compliance requirements.
Maintenance
With ETL, data is transformed via a secondary processing server before it's loaded into the warehouse. On-premise, server-based ETL processes demand regular IT maintenance because they have fixed tables, timelines, and repetitive data selection for loading and transformation. Some newer automated, cloud-based ETL solutions require less upkeep.
In comparison, ELT is considered a cloud-native process. ELT requires minimal maintenance since data is almost instantly accessible and its transformation is automated and cloud-based. It relies on automated solutions, not on the user to initiate manual updates.
Hardware
Conventional, on-premises ETL requires costly hardware, while the ELT process is inherently cloud-based, eliminating the need for secondary equipment.
Comparison of ETL and ELT
| Capability | ETL | ELT |
|---|---|---|
| Acronym definition | Extract, transform, and load | Extract, load, and transform |
| Process | Extract raw data from relevant sources. The extracted data is transformed to fit the desired format or structure, often involving cleansing, filtering, aggregation, and enrichment. Then the data is loaded into a target data warehouse or data lake. | Extract raw data from relevant sources. Load it into a data warehouse or data lake in its raw state. Transformations are performed after the data is loaded within the target system. |
| Data volume | Best suited to small data sets that require complex transformations. | Works with data of any size or volume. |
| Data compatibility | Ideal for structured data. | Works with all data types, including structured, semi-structured, and unstructured. |
| Speed | Time-intensive process because data is transformed before it's loaded into the target system. | Faster than ETL because it uses resources within the data warehouse to transform data. |
| Costs | Can be costly to set up and process data, mainly due to external data transformation. | Generally more cost efficient and flexible because it’s cloud-based. |
| Security | Fulfilling data protection requirements may involve developing custom applications. | Uses integrated security and privacy features within data warehouses. |
| Maintenance | Uses integrated security and privacy features within data warehouses. Secondary processing server adds to maintenance responsibilities. | Lower maintenance requirements than ETL due to simplified data stack. |
| Hardware | On-premises ETL requires costly hardware. | ELT is a cloud-based process, eliminating the need for hardware. |
ETL vs ELT: What are the similarities?
As their names suggest, there are a few key similarities between these two approaches to data processing. ETL and ELT are both processes that prepare data for analysis in three key steps. Here are their similarities in more detail.
Extraction
The first step in both ETL and ELT is data extraction. This involves gathering raw data from a range of sources, such as files, databases, and event logs through process mining, and more. With ELT, the data you collect can be in any form or structure, from documents to images.
Transformation
Transformation is the second step of the ETL process, while it’s the third step of the ELT process. During transformation, raw data is changed from its original structure into a format that meets the requirements of the target system you’ll use to store it for analysis.
Transformation involves defining rules that will clean and prepare the data for analytics. These rules for transformation may include eliminating inaccuracies, changing data formats, and removing personally identifiable information (PII).
Load
The load phase involves moving and storing data in its target system. This is the final stage of the ETL process, and second stage of ELT. With ETL, you’re loading data that’s been transformed to the required format, enabling reporting tools to generate actionable reports and insights. Whereas, in the ELT process, you’ll transform the extracted data after this stage.
When to use ETL vs. ELT
Although ETL and ELT are both valuable, there are specific scenarios where each one will be more useful to your organization.
Process mining and discovery
Process mining requires understanding how your processes actually work, not just how they’re designed to work. Getting to the bottom of this real-life process requires raw, untransformed event data. But because traditional ELT tools transform data before loading it, they aren’t ideal for this work. In contrast, ELT does load the raw data directly into the process mining tool, letting businesses more quickly discover insights without the need to get IT heavily involved.
Data experimentation
Data engineers in large organizations often perform experiments with data. This includes testing new approaches to address business problems, or finding hidden data sources for analysis. During experimentation, ETL is valuable for understanding database functionality in different scenarios.
Database migration
Since ETL emerged in the 1970s, it’s traditionally required on-premise databases or servers. For this reason, if your organization needs to transfer on-site data to a cloud-based data warehouse, ETL might be the best choice. This is most relevant for organizations experiencing a merger, or reducing their physical office space.
Real-time data retrieval
Organizations within industries like financial services and transportation typically need access to real-time, current data to support decision-making and inform business intelligence. ELT is useful for rapidly transforming data and making it available for analysis.
Data-intensive organizations
If your organization handles large quantities of data, whether they’re structured or unstructured, you’ll benefit from using ELT. ELT enables you to process large datasets quickly, making it an ideal scalable solution to support you as your business grows.
Which is right for you: ETL or ELT?
What if you could extract and manage business-wide data, while eliminating the need for manual processing? ABBYY Timeline does just that.
Timeline is our market-leading process mining software platform that distills complex data out of the box. Timeline can extract data from practically any business system, including legacy systems, packaged applications, and data warehouses.
The built-in ETL tool enables line-of-business users to load event log data without the need for complex ETL tools and immediately visualize “as is” process flows to see the delays, bottlenecks, and outliers. It offers real-time insights to uncover process improvement opportunities and predict future outcomes.
As a cloud-first platform, ABBYY Timeline is available 24/7/365. This means features like performance measurement, security, and compliance are always ready to use and happen automatically.
Request a demo to see ABBYY Timeline in action, and read our whitepaper to understand how data transformation methods impact process mining and discovery.

Andrew Pery
Digital transformation expert and AI Ethics Evangelist for ABBYY
Andrew Pery is an AI Ethics Evangelist at intelligent automation company ABBYY. His expertise is in artificial intelligence (AI) technologies, application software, data privacy and AI ethics. He has written and presented several papers on the ethical use of AI and is currently co-authoring a book for the American Bar Association. He holds a Masters of Law degree with Distinction from Northwestern University Pritzker School of Law and is a Certified Information Privacy Professional (CIPP/C), (CIPP/E) and a Certified Information Professional (CIP/AIIM).
Connect with Andrew on LinkedIn.