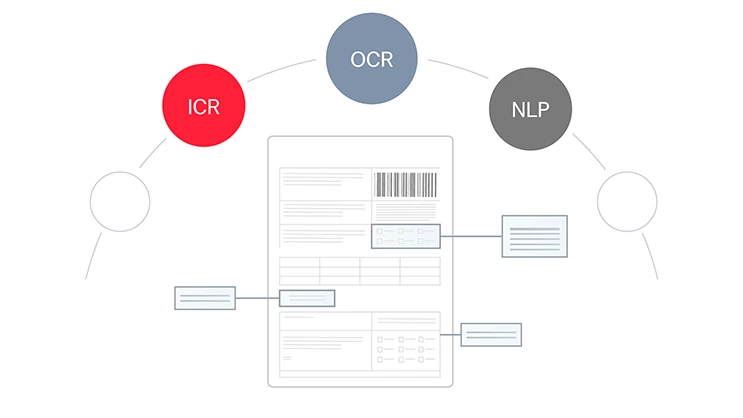
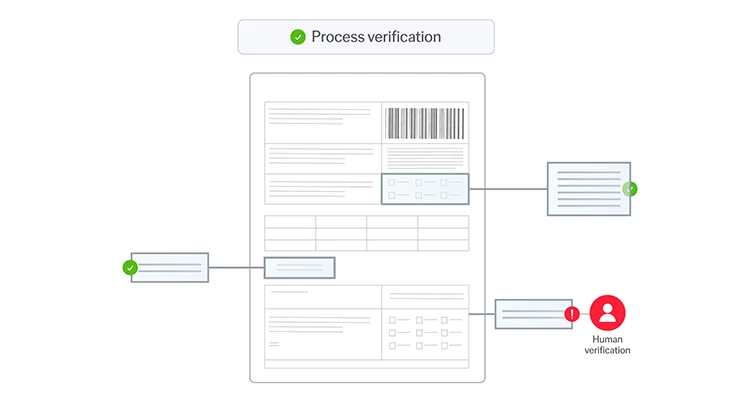
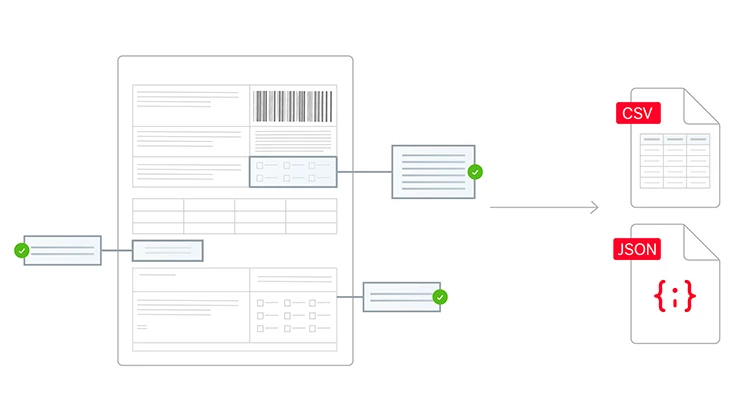
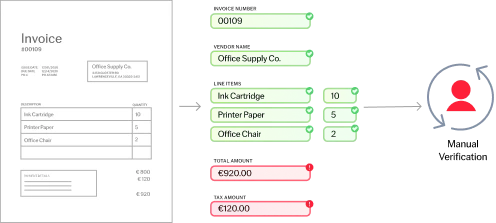
Alle Dokumente, alle Sprachen, alle Komplexitätsgrade
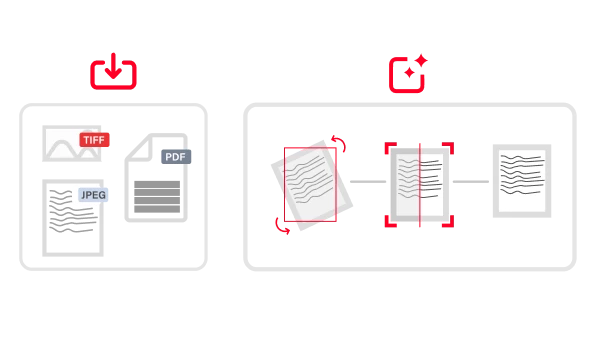
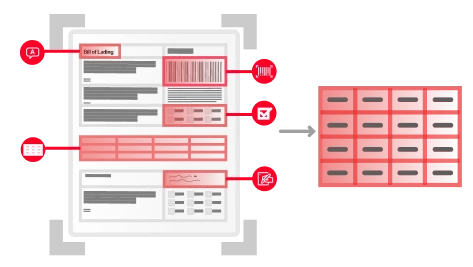
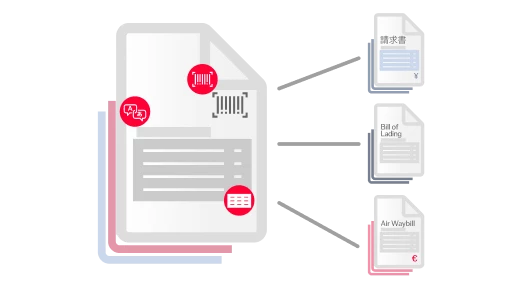
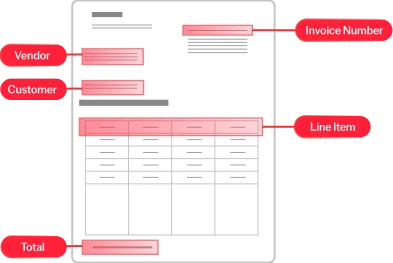
Die Purpose-Built-AI von ABBYY verarbeitet strukturierte (z.B. Steuerformulare), halbstrukturierte (z.B. Rechnungen) und unstrukturierte (z.B. Verträge) Dokumente in über 200 Sprachen. Sie extrahiert effizient geschäftskritische Daten aus mehrseitigen Dokumenten und komplexen Tabellen und sorgt so für reibungslose, automatisierte Arbeitsabläufe in Ihrem Unternehmen.