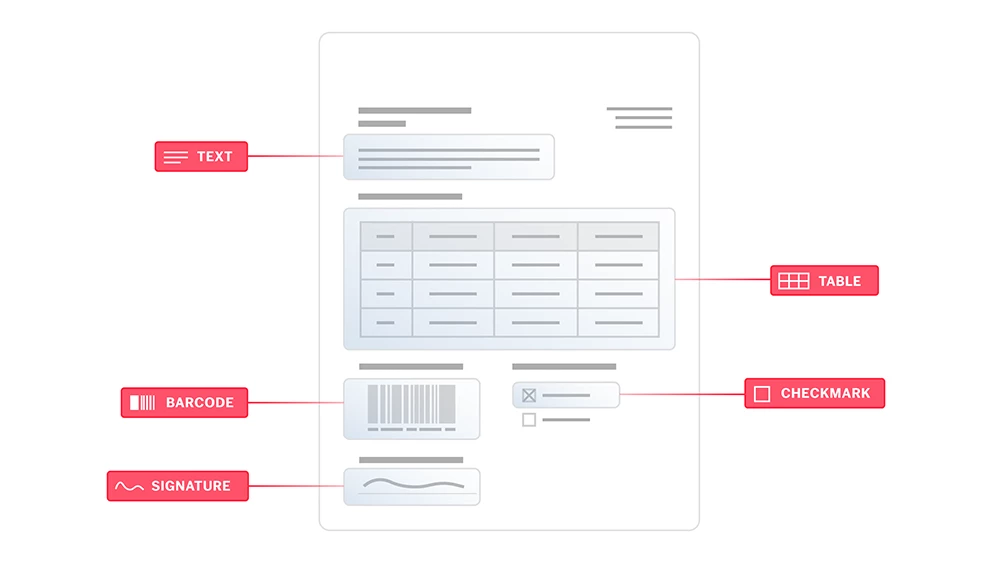
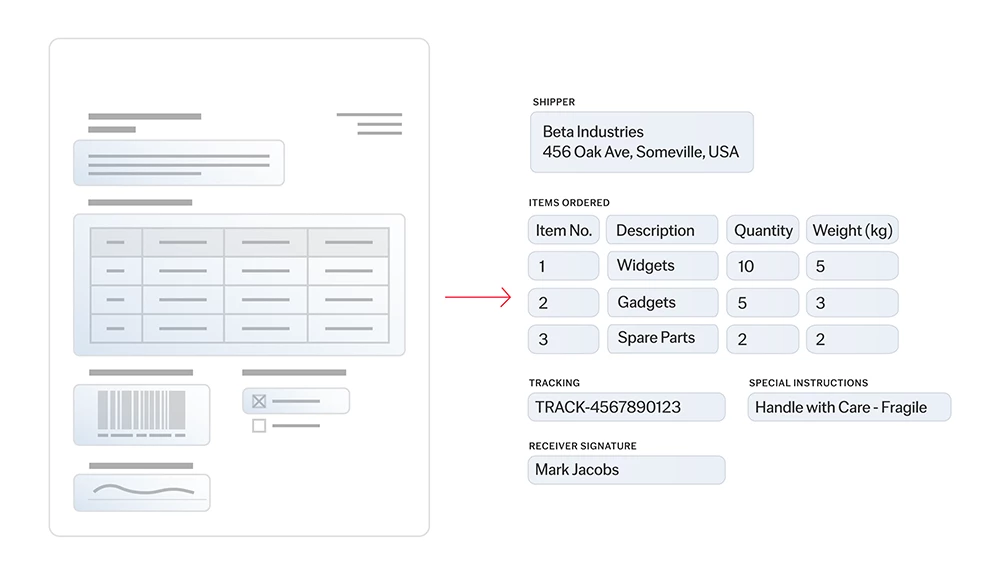
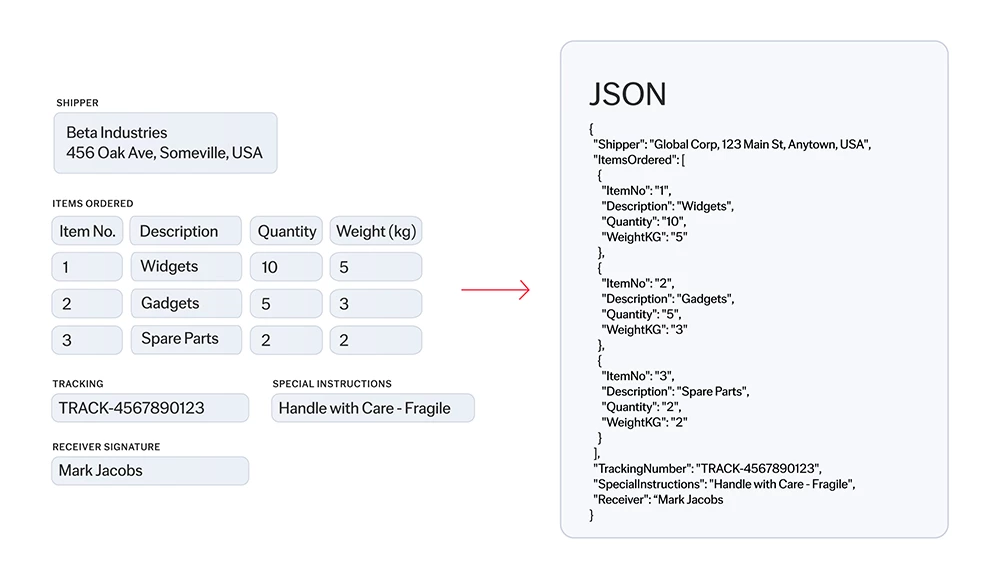
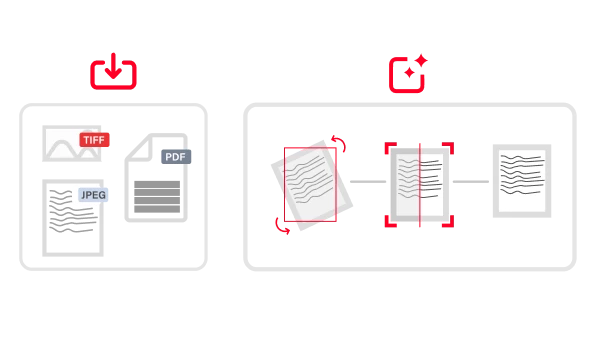
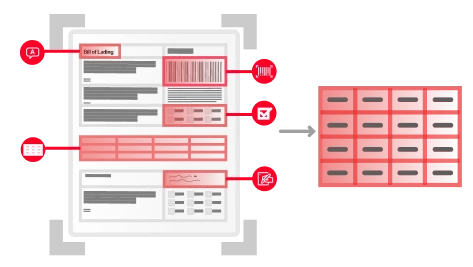
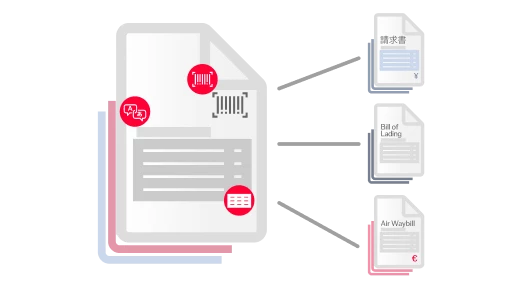
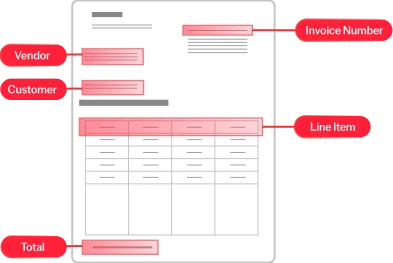
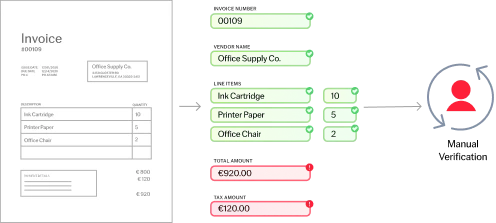
Die Texterkennung (Optical Character Recognition, OCR) ist eine Technologie, mit der Dokumente verschiedener Art, wie gescannte Papierdokumente, PDF-Dateien oder Bilder, in bearbeitbare und durchsuchbare Daten umgewandelt werden können. ABBYY OCR identifiziert und verarbeitet mittels hochentwickelter Algorithmen und maschinellen Lernens gedruckte Zeichen, erkennt das Layout und die logische Struktur von Dokumenten und konvertiert ihren Inhalt in strukturierten, maschinenlesbaren, KI-fähigen Text. Auf diese Weise können Unternehmen große Mengen an papierbasierten Daten präzise und effizient digitalisieren.
Präzise OCR ist eine entscheidende Komponente der intelligenten Dokumentenverarbeitung. Sie gewährleistet eine genaue Datenextraktion und -ausgabe und steigert so die Effizienz des Unternehmens. Eine ungenaue Datenextraktion kann zu Fehlinformationen führen, die Entscheidungsfindung behindern und Geschäftsabläufe beeinträchtigen. Erhöhter manueller Arbeitsaufwand, höhere Kosten und geringere Produktivität sind die Folge. Durch die Erschließung von Inhalten und Erkenntnissen aus Dokumenten ermöglicht präzise OCR eine nahtlose Automatisierung und unterstützt intelligentere Entscheidungsprozesse. Sie ist das Rückgrat von KI-basierten Automatisierungsworkflows und wandelt unstrukturierte Daten in umsetzbare Informationen um, die in fortschrittlichen Technologielösungen eingesetzt werden können.