La inteligencia artificial de ABBYY
Purpose-Built AI Center (Centro de inteligencia artificial específica)
Tu espacio central para obtener información sobre las vanguardistas herramientas de IA de ABBYY - obtén datos precisos para impulsar la automatización de tus procesos empresariales.

En las soluciones de ABBYY empleamos una combinación de tecnologías que ofrecen el mejor procesamiento inteligente de documentos (IDP, por sus siglas en inglés) de su clase.
La plataforma IDP de ABBYY integra una innovadora IA en todos los pasos de la cadena de procesamiento inteligente de documentos, desde la mejora de imágenes hasta la detección de objetos, OCR/ICR, clasificación, extracción de documentos semiestructurados y extracción de documentos no estructurados.
Gracias a la combinación adecuada de tecnologías y técnicas, las soluciones ABBYY IDP pueden procesar cualquier tipo de documento: cualquier formato, cualquier idioma, cualquier estructura. Todas nuestras técnicas especializadas se han optimizado para obtener las mejores inferencias posibles utilizando la menor cantidad de recursos, de modo que tengan un coste óptimo y ofrezcan el mayor retorno de la inversión a nuestros clientes.
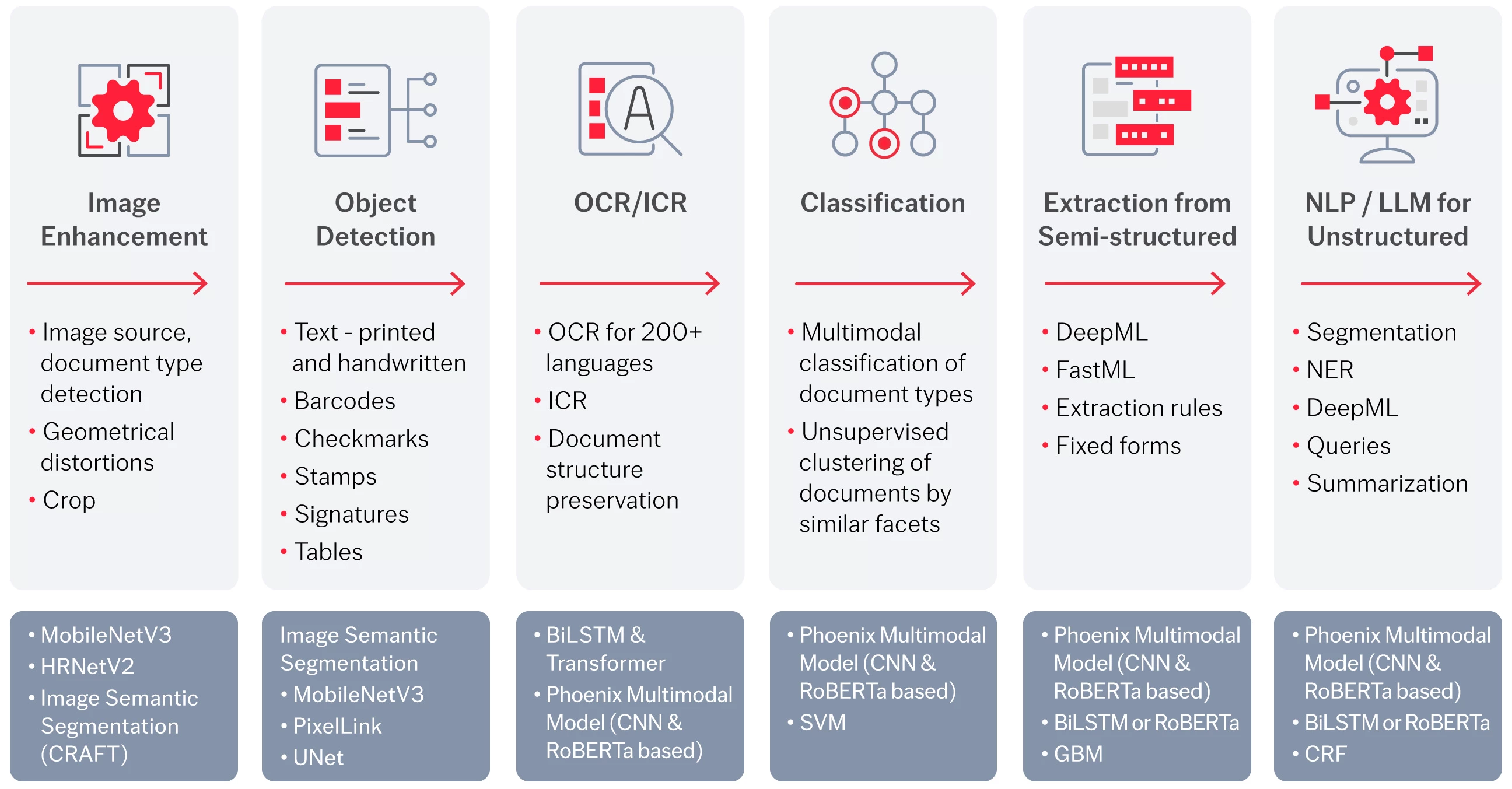
Herramientas de IA de última generación para las soluciones específicas de ABBYY
Una combinación de modelos y algoritmos de IA altamente optimizados para la tarea.
Phoenix 1.0
Phoenix 1.0 es un modelo multimodal de vanguardia que combina el análisis avanzado de imágenes y texto mediante la integración de redes neuronales convolucionales (CNN) para procesar datos visuales con el modelo lingüístico RoBERTa de comprensión de textos. Phoenix cuenta con una innovadora canalización basada en IA que ofrece funciones de extracción de pares clave-valor sin intervención, automatizando las tareas más complejas de la formación de modelos de documentos. A diferencia de otros modelos lingüísticos más amplios que abordan una amplia gama de tareas de comprensión del lenguaje, Phoenix ofrece un marco más sólido para procesar documentos, sobre todo con datos multimodales. Ofrece capacidades mejoradas en la extracción de características, eficiencia en los flujos de trabajo de procesamiento y una comprensión más profunda del contexto que los modelos lingüísticos amplios, por sí solos, no son capaces de alcanzar plenamente. Esta especialización lo convierte en la opción ideal para casos prácticos que dependen en gran medida de la información transmitida mediante documentos, ya que garantiza que los datos se procesen con precisión y rapidez.
Phoenix se ha desarrollado con el objetivo de mejorar la eficiencia y eficacia de las tareas de procesamiento de documentos. Al aprovechar los puntos fuertes de las redes neuronales convolucionales para analizar imágenes junto con la comprensión lingüística avanzada de RoBERTa, esta integración permite una comprensión matizada de documentos complejos que contienen elementos tanto textuales como visuales. Gracias a este enfoque centrado, las empresas pueden lograr una precisión superior en la extracción y el análisis de la información en comparación con el uso de modelos de propósito general. Además, su diseño minimiza el consumo de recursos porque agiliza el flujo de trabajo de procesamiento, lo que, en última instancia, mejora la velocidad y reduce los costes operativos. Por consiguiente, las organizaciones pueden procesar los documentos de forma más eficiente, lo que aporta un valor considerable en el ámbito del procesamiento de documentos y mejora la productividad general.
Aprendizaje automático (Machine Learning)
Nuestro procesamiento inteligente de documentos utiliza una combinación de tecnologías para ofrecer un rendimiento inigualable. Una combinación de aprendizaje automático profundo y aprendizaje automático rápido maximiza la tasa de procesamiento directo (STP, por sus siglas en inglés). Con nuestros modelos de IA específicos según documento, preentrenados mediante aprendizaje automático profundo, nuestros clientes pueden alcanzar hasta un 90 % de precisión desde el primer momento. Y con la inclusión del aprendizaje automático rápido, esta precisión supera el 95 %. El aprendizaje automático rápido memorizará los valores atípicos que el aprendizaje automático profundo no logra gestionar y trabaja rápidamente con tan solo unas pocas variaciones de los documentos en cuestión. Ademas, a partir de la información que recopilamos de ese proceso, nuestro aprendizaje profundo mejora continuamente para ofrecer una precisión cada vez mayor con el paso del tiempo.
El aprendizaje profundo nos permite preentrenar modelos de IA específicos para tareas de procesamiento de documentos. A diferencia de los LLM de uso general o Gen AI, que están diseñados para una amplia gama de tareas, nuestros modelos de aprendizaje profundo destacan en su propósito especializado, proporcionando resultados más fiables y precisos.
- El aprendizaje automático profundo (ML, por sus siglas en inglés) utiliza CNN (redes neuronales convolucionales), RNN (redes neuronales recurrentes) y NLP (procesamiento del lenguaje natural) para extraer información de documentos semiestructurados. Generaliza los distintos formatos de documento, manejando eficazmente diseños desconocidos sin depender de plantillas. Aunque para una extracción precisa de los campos requiere una cantidad considerable de datos etiquetados (entre 500 y 10 000 documentos), este amplio proceso de entrenamiento garantiza una gran precisión, lo que la convierte en una potente herramienta para la interpretación de datos complejos.
- El aprendizaje automático rápido (ML, por sus siglas en inglés) se centra en patrones textuales y visuales y trabaja de manera eficaz incluso con tan solo uno o dos documentos por conjunto. Utiliza una tecnología que agrupa los documentos con un diseño de aspecto similar y entrena internamente un modelo de extracción de campos para cada grupo. A diferencia del ML profundo, este enfoque se centra en las variaciones en los documentos que ya ha "visto" en lugar de generalizar los patrones. Su clara ventaja es que acelera el proceso de aprendizaje, requiere menos potencia de CPU y los tiempos de procesamiento son más cortos.
OCR e ICR: reconocimiento óptico de caracteres y reconocimiento de escritura a mano
ABBYY es pionera en tecnología de reconocimiento óptico de caracteres, ya que lleva investigando e innovando activamente en este campo desde 1993, cuando salió al mercado ABBYY FineReader, nuestro primer «sistema OCR omnifont». A lo largo de los años, la tecnología ha evolucionado desde el reconocimiento de caracteres individuales, la identificación de palabras y la reproducción de la estructura de la página hasta la aplicación de la tecnología de reconocimiento adaptativo de documentos (ADRT®), que comprende los documentos en su totalidad, incluido el diseño, la estructura multipágina y elementos como el encabezado, el pie de página y el índice.
Con los avances de la IA, los últimos años ABBYY ha desarrollado y consolidado su enfoque integral del OCR y el ICR. Este enfoque utiliza las mismas tecnologías que conforman la base de las herramientas de IA generativa: redes neuronales evolutivas, transformadores y modelos lingüísticos.
La red neuronal circunvolucional descompone una imagen de texto manuscrito o impreso en un documento en sus bits y bytes, intentando dar sentido a lo que realmente es. Toda esa información procedente de la CNN pasa a un transformador, que proporciona un posible pronóstico para una palabra. A continuación, introducimos nuestro propio LM, que se ha entrenado con miles de millones de parámetros y cuenta con la función específica de poder analizar el contexto de todas las palabras de un grupo y llegar a una conclusión en base a esa información. Esta técnica mejora drásticamente el rendimiento y la precisión de nuestras capacidades OCR e ICR en general, y se aplica en combinación con nuestro enfoque estadístico. Nuestra inteligencia artificial decidirá automáticamente qué enfoque se adapta mejor a los casos de uso de tus documentos para optimizar sobre la marcha la coherencia, la precisión y la velocidad, lo que se traduce en mejores índices de procesamiento directo.
Visión por ordenador (Computer Vision)
ABBYY convierte la avanzada tecnología de visión por ordenador en uno de los componentes clave de sus soluciones de procesamiento inteligente de documentos para mejorar la automatización y la extracción de datos de documentos complejos. Mediante la integración de redes neuronales, incluidas las redes neuronales circunvolucionales (CNN) y transformadores, ABBYY procesa contenidos visuales como texto, imágenes e incluso documentos manuscritos. Las CNN descomponen los elementos visuales de los documentos, identificando patrones en el texto impreso o manuscrito, mientras que los transformadores analizan el contexto para mejorar la precisión del reconocimiento de palabras y caracteres. Esta tecnología permite a ABBYY interpretar y clasificar con precisión una amplia gama de tipos de documentos, desde formularios estructurados hasta contenidos no estructurados con mucho texto.
Además, las soluciones de ABBYY incorporan técnicas de detección de objetos para identificar características como códigos de barras, firmas y sellos, esenciales para aplicaciones en sectores como los seguros y la logística. Al combinar la visión por ordenador con modelos lingüísticos y otras tecnologías de IA, ABBYY mejora las capacidades de procesamiento de documentos, lo que permite a las empresas automatizar los flujos de trabajo de forma más eficaz, reducir los errores manuales y mejorar las tasas de procesamiento directo.
Procesamiento del lenguaje natural
El hecho de que ABBYY haya implantado el procesamiento del lenguaje natural (natural language processing - NLP) en sus soluciones de procesamiento inteligente de documentos ofrece ventajas transformadoras a las empresas que buscan optimizar sus procesos de gestión documental. La plataforma Vantage de ABBYY destaca en la extracción eficaz de datos estructurados de documentos estructurados y no estructurados debido a que utiliza técnicas avanzadas de NLP como el reconocimiento de entidades con nombre (NER), el aprendizaje automático profundo (DeepML) y el resumen. Mediante la integración de capacidades de aprendizaje profundo, la plataforma proporciona un sistema de NLP personalizable que se adapta a requisitos empresariales únicos. Tanto los desarrolladores como los usuarios empresariales pueden entrenar estos sistemas para que reconozcan entidades con nombre personalizadas, lo que garantiza una solución a medida al tiempo que se mantiene la transparencia y el control sobre los modelos utilizados. Esta capacidad facilita unas operaciones comerciales más rápidas y precisas, tal como pone de manifiesto la aceleración de la tramitación de préstamos y la agilización de la gestión de contratos.
Utilizar las capacidades de NLP de ABBYY aporta notables ventajas a los entornos empresariales. Entre ellas figuran una mayor eficacia operativa gracias a la automatización de tareas documentales rutinarias, significativas mejoras en la precisión y fiabilidad de la extracción de datos y un aumento de la velocidad de procesamiento que favorece la agilización de los procesos de toma de decisiones. Además, las soluciones de ABBYY desempeñan un papel decisivo en la gestión de la conformidad y la privacidad de los datos, ya que identifican con precisión la información confidencial de acuerdo con la normativa legal. Sectores como la banca, las finanzas, la abogacía y la sanidad son los que mayor provecho obtienen de estas técnicas avanzadas, como la segmentación, la generación de consultas y el resumen. Estas herramientas permiten a las organizaciones convertir datos brutos en información práctica, mejorando así la prestación de servicios a los clientes e impulsando la eficiencia operativa en todos los ámbitos.
NeoML
NeoML es el marco integral de aprendizaje automático de código abierto de ABBYY, diseñado para satisfacer tanto las tareas de aprendizaje profundo como las de aprendizaje automático tradicional. Esta versátil herramienta admite más de 100 tipos de capas de redes neuronales y más de 20 algoritmos tradicionales de aprendizaje automático, lo que permite adaptarla a una amplia gama de aplicaciones, como la visión por ordenador y el procesamiento del lenguaje natural. La compatibilidad de NeoML con entornos multiplataforma, incluidos Windows, Linux, macOS, iOS y Android, garantiza una integración perfecta en las infraestructuras empresariales existentes. Además, NeoML es compatible con el formato Open Neural Network Exchange (ONNX), lo que le permite interoperar con otras herramientas de aprendizaje automático y así mejorar aún más su utilidad en diversos entornos de programación mediante lenguajes como C++, Java y Objective C.
Para las empresas, NeoML es una solución sólida, escalable y rentable que les permite implantar modelos de aprendizaje automático en diversas funciones empresariales. Su naturaleza de código abierto, que cuenta con una licencia Apache 2.0, significa que las organizaciones pueden adaptar NeoML a sus necesidades específicas sin incurrir en elevados costes, maximizando así la eficiencia en la asignación de recursos. Gracias al amplio apoyo de la comunidad, NeoML mejora y se actualiza continuamente, lo que garantiza a las empresas el acceso a las funciones de aprendizaje automático más avanzadas. El alto rendimiento de la plataforma, que admite tanto CPU como GPU, se traduce en una gran rapidez a la hora de procesar datos y obtener resultados, lo que la convierte en la opción ideal para las empresas que buscan aprovechar el aprendizaje automático para impulsar la innovación y optimizar la eficiencia operativa.

Carlsberg
U.S. FDA
Emerson
Carlsberg acelera la comercialización de bebidas
Aceleración
de las entregas y satisfacción del cliente
140+
horas ahorradas al mes
Un 92%
del procesamiento de pedidos se lleva a cabo sin contacto

Gracias al procesamiento inteligente de documentos, Carlsberg transformó digitalmente sus procesos de pedido y entrega.
U.S. FDA utiliza el IDP para proteger la salud pública
Más de un 99%
de precisión en la captura de los detalles críticos
120+
campos complejos en dos docenas de formularios
30
años de archivo de formularios transformados

«ABBYY nos ha traído al siglo XXI».

Mejorar el recorrido del cliente con Process Intelligence

“Process Intelligence de ABBYY nos ha ayudado a realizar un verdadero cambio cultural: confiar en los datos y realizar mejoras basadas en ellos.”
- Simon Higgs, Director of Business Transformation
Las empresas líderes del mundo confían en ABBYY
Más de 10 000 clientes
incluidas muchas empresas Fortune 500 confían en ABBYY.
Más de 400 patentes
y solicitudes de patente. Amplio liderazgo tecnológico en automatización inteligente de procesos.
Más de 30 años de experiencia
proporcionando soluciones de automatización inteligentes a empresas de todo el mundo.
Nuestros principios para una IA fiable
Compromiso con la ciencia de datos responsable
Estamos comprometidos con el desarrollo riguroso de productos basados en los principios responsables de la ciencia de datos, como la confidencialidad, la precisión y la seguridad, integrados en nuestra cartera de productos de procesamiento inteligente de documentos e inteligencia de procesos impulsados por IA.
Protección de la confidencialidad de los datos personales
Incorporamos metodologías de privacidad por diseño que permiten a nuestros clientes controlar y limitar la recogida y el tratamiento de información personal.
Garantía de precisión y calidad de los productos
Desarrollamos nuestra cartera de productos basados en IA cumpliendo fielmente las normas del sector en cuanto a precisión de la información.
Conforme a las normas de seguridad del sector
Aplicamos principios de seguridad de confianza cero diseñados para minimizar los riesgos en ciberseguridad.


El enfoque de ABBYY sobre la IA ética
La IA específica aporta valor y utilidad a las empresas
- La IA específica aporta valor y utilidad a las empresas
- Estamos comprometidos con los marcos de gestión de riesgos de la IA para proporcionar un enfoque estructurado para evaluar los riesgos a lo largo del ciclo de vida de nuestra cartera de productos habilitados para IA.
- Nos comprometemos a cumplir la normativa aplicable en materia de privacidad de datos e IA.



