Intelligence artificielle d'ABBYY
Purpose-Built AI Center (Centre d’IA conçu sur mesure d’ABBYY)
Votre point central pour obtenir des informations sur les outils d'IA de pointe d'ABBYY — fournissant des données précises pour alimenter l'automatisation des processus métier.

Au cœur des solutions ABBYY, nous utilisons un mélange de technologies pour fournir le meilleur de l’IDP (traitement intelligent des documents).
La plateforme IDP d’ABBYY utilise une IA innovante à chaque étape du traitement intelligent des documents, depuis l’amélioration des images jusqu’à la détection des objets, en passant par l’OCR/ICR, la classification, l’extraction à partir de documents semi-structurés et à partir de documents non structurés.
En utilisant la bonne combinaison de technologies et de techniques, les solutions IDP d’ABBYY peuvent traiter tout type de document — quel que soit le format, la langue ou la structure. Toutes nos techniques spécialisées ont été optimisées pour fournir les meilleures inférences possibles avec un minimum de ressources nécessaires, afin d'offrir un coût optimal et un retour sur investissement maximal pour nos clients.
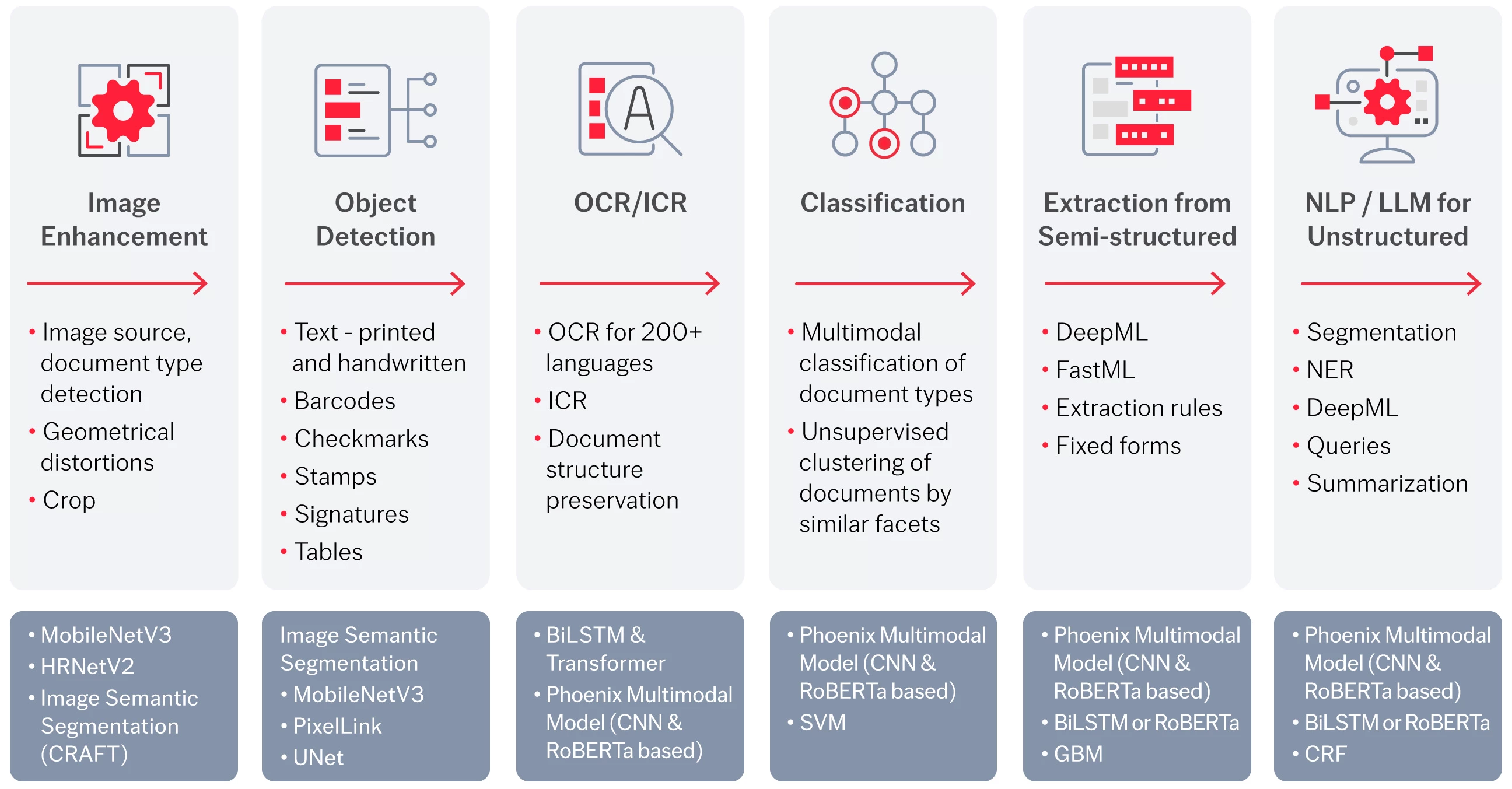
Des outils d’IA de pointe alimentent les solutions sur mesure d’ABBYY
Une combinaison de modèles et d’algorithmes d’IA hautement optimisés pour les tâches à effectuer.
Phoenix 1.0
Phoenix 1.0 est un modèle multimodal révolutionnaire qui analyse de façon très performante le texte et les images en associant les CNN (Réseaux neuronaux Convolutifs), pour le traitement des données visuelles, au modèle de langage RoBERTa, pour la compréhension du texte. Phoenix est doté d’un pipeline innovant fonctionnant grâce à l’IA qui permet l’extraction de valeurs et d’éléments-clés et d’automatiser les tâches documentaires les plus fastidieuses, avec un apprentissage quasi-nul. Contrairement aux plus grands modèles de langage conçus pour une large palette de tâches de compréhension du langage, Phoenix fournit un cadre plus robuste au traitement des documents, en particulier s’agissant des données multimodales. Il est doté de fonctionnalités renforcées d’extraction des caractéristiques, il est plus efficace dans le traitement des flux et comprend mieux le contexte, ce que les grands modèles de langage seuls ne parviennent pas à faire. Cette spécialisation en fait le choix idéal pour toutes les utilisations qui s’appuient largement sur les informations transmises via des documents ; elle garantit un traitement précis des données et des délais d’exécution rapides.
Phoenix a été développé en mettant l’accent sur les gains d’efficacité et d’efficience dans les tâches de traitement des documents. En exploitant au mieux les atouts des CNN pour l’analyse des images et la compréhension de pointe du langage avec RoBERTa, cette intégration permet de comprendre toutes les nuances de la complexité des documents qui contiennent tant du texte que des éléments visuels. Cette approche spécialisée signifie que les entreprises peuvent obtenir une précision supérieure de l’extraction et l’analyse des informations à celle obtenue avec des modèles génériques. De plus, sa conception minimise la consommation de ressources en rationalisant le traitement des flux. En conséquence, cela améliore la vitesse et fait baisser les coûts de fonctionnement. Ainsi, les entreprises peuvent traiter les documents plus efficacement, dégager plus de valeur dans le cadre du traitement des documents et améliorer leur productivité dans son ensemble.
Machine learning
Notre IDP tire le meilleur parti d’un mélange de technologies, pour une performance incomparable. Un mélange de machine learning profond (deep) et de machine learning rapide (fast) maximise le taux de traitement d’une traite. Avec nos modèles spécifiques d’IA pour les documents, déjà entraînés avec le deep machine learning, nos clients peuvent obtenir dès le départ un taux de précision allant jusqu’à 90%. Mais avec l’ajout du fast machine learning, ce taux dépasse les 95%. Le fast machine learning mémorise les anomalies qui n’auraient pas été détectées par le deep machine learning. Il agit rapidement, avec juste quelques variations des documents en question. Et, grâce aux données que nous obtenons de ce processus, notre deep learning s’améliore en permanence, pour toujours plus de précision au fil du temps.
Le deep learning nous permet de pré-entrainer nos modèles d’IA spécifiquement pour les tâches de traitement des documents. Contrairement aux LLM ou modèles d’IA génériques, conçus pour une large palette de tâches, nos modèles de deep learning excellent dans leur spécialité, pour des résultats plus fiables et plus justes.
- Le Deep machine learning (ML) utilise les CNN (réseaux neuronaux convolutifs), les RNN (réseaux neuronaux récurrents), et le NLP (traitement du langage naturel) pour extraire des informations des documents semi-structurés. Il est généraliste, pour différents formats de documents, gérant efficacement les mises en page non détectées sans s’appuyer sur les maquettes (templates). Bien qu’il nécessite une quantité importante de données étiquetées — de 500 à 10 000 documents — pour que l’extraction des champs soit juste, le processus étendu d’entraînement garantit une précision élevée, ce qui en fait un outil puissant pour l’interprétation de données complexes.
- Le Fast machine learning (ML) se concentre sur les schémas visuels et textuels et s’avère efficace avec seulement un ou deux documents par lot. Il a recours à une technologie de regroupement qui rassemble des mises en page de documents similaires et entraîne en interne un modèle d’extraction des champs pour chaque groupe. Contrairement au deep ML, cette approche se concentre sur les variations des documents déjà « vus » plutôt que sur une généralisation des schémas. Son avantage le plus évident est qu’elle accélère le processus d’apprentissage, nécessite moins de puissance informatique et réduit les temps de traitement.
OCR & ICR – reconnaissance optique de caractères et reconnaissance de l’écriture manuscrite
ABBYY est pionnier dans la technologie de reconnaissance optique de caractères, menant activement des recherches et lançant des innovations dans ce domaine depuis 1993, année de lancement d’ABBYY FineReader, notre premier « système OCR toutes polices de caractères ». Au fil des ans, cette technologie a évolué de la reconnaissance de caractères individuels, l’identification de mots et la reproduction de la structure des pages à l’application d’une technologie adaptive de reconnaissance des documents (ADRT®) qui comprend les documents dans leur intégralité, y compris la mise en page, la structure de chaque page, et des éléments comme les en-têtes, pieds-de-page ou sommaires.
Avec les progrès de l’IA, ces dernières années, ABBYY a développé et consolidé son approche d’A à Z de l’OCR et de l’ICR. Cette approche utilise les mêmes technologies que celles qui sont à la base des outils d’IA générative – les réseaux neuronaux convolutifs (CNN), les transformateurs, et les modèles de langage.
Les réseaux neuronaux convolutifs divisent en bits et en bytes les images de textes manuscrits ou dactylographiés figurant dans un document pour tâcher de comprendre ce dont il s’agit. Tout cet input obtenu avec les CNN alimente ensuite un transformateur qui tirera un potentiel résultat de chaque mot. Ensuite, notre propre LM, entraîné avec des milliards de paramètres, entre en scène. Son rôle : être capable de saisir le contexte de tous les différents mots au sein d’un groupe et tirer une conclusion de ces informations. Cette technique améliore de façon spectaculaire la performance et la précision de l’ensemble de nos fonctionnalités d’OCR et d’ICR. Elle est optimisée par son association à notre approche statistique : notre IA décidera automatiquement quelle approche et la meilleure pour vos propres documents afin d’optimiser à la volée la cohérence, la précision et la rapidité. Résultat : de meilleurs taux de traitement d’une traite.
Vision par ordinateur
ABBYY tire le meilleur parti de sa technologie de pointe de vision par ordinateur, élément-clé de ses solutions de traitement intelligent des documents, pour améliorer l’automatisation et l’extraction des données avec des documents complexes. En y intégrant des réseaux neuronaux, y compris des CNN et des transformateurs, ABBYY peut traiter les contenus visuels comme les textes, les images, et même les documents manuscrits. Les CNN divisent les éléments visuels des documents en identifiant les schémas dans les textes dactylographiés ou manuscrits, tandis que les transformateurs analysent le contexte pour gagner en précision dans la reconnaissance des mots et des caractères. Cette technologie permet à ABBYY d’interpréter et de classer de façon juste une large gamme de types de documents, allant de formulaires structurés à du contenu riche en texte non structuré.
De plus, les solutions ABBYY intègrent des techniques de détection d’objets pour identifier des caractéristiques telles que les codes-barres, les signatures ou les tampons, essentiels dans des domaines d’activité tels que l’assurance ou la logistique. En associant la vision par ordinateur à des modèles de langage et d’autres technologies d’IA, ABBYY améliore les fonctionnalités de traitement des documents et permet aux entreprises d’automatiser leurs flux de travail plus efficacement, de réduire les erreurs manuelles et d’améliorer les taux de traitement d’une traite.
NLP – traitement du langage naturel
L’intégration par ABBYY du traitement du langage naturel (NLP) à ses solutions de traitement intelligent des documents (IDP) donne un avantage transformationnel aux entreprises cherchant à optimiser leurs processus de gestion des documents. Grâce à des techniques NLP de pointe telles que la NER (segmentation d’entités), le DeepML (deep machine learning), ou la synthétisation, la plateforme ABBYY Vantage excelle dans l’extraction efficace de données structurées, à partir de documents tant structurés que non structurés. Grâce à l’intégration de fonctionnalités de deep learning, cette plateforme constitue un système personnalisable de NLP qui s’adapte aux besoins uniques de chaque entreprise. Tant les développeurs que les utilisateurs en entreprise peuvent exercer ces systèmes à reconnaître des entités spécifiques, ce qui offre une solution sur mesure tout en garantissant le même niveau de transparence et de maîtrise des modèles utilisés. Cette capacité facilite les opérations de l’entreprise qui sont ainsi plus rapides et plus précises, comme en témoignent par exemple un traitement accéléré des demandes de prêts ou une gestion optimisée des contrats.
Cette application des fonctionnalités NLP d’ABBYY procure de nombreux avantages dans les entreprises. Parmi eux, une meilleure efficacité opérationnelle grâce à l’automatisation des tâches de routine en lien avec les documents, une amélioration notable de la justesse et de la fiabilité de l’extraction des données, et une plus grande vitesse de traitement qui favorise des prises de décision plus rapides. De plus, les solutions ABBYY sont déterminantes dans la gestion de la conformité et des données personnelles car elles identifient avec précision les informations sensibles, dans le respect des normes réglementaires. Des secteurs d’activité comme la banque, la finance, le juridique et la santé sont particulièrement bien adaptés à l’utilisation optimale de ces techniques de pointe, y compris la segmentation, la génération de requêtes et la synthétisation. Ces outils permettent aux organisations de convertir des données brutes en informations exploitables, ce qui se traduit par un meilleur service aux clients et qui booste l’efficacité opérationnelle à tous les niveaux.
NeoML
NeoML est le cadre exhaustif en open-source de machine learning d’ABBYY conçu pour gérer les tâches de deep learning et de machine learning traditionnel. Cet outil polyvalent est compatible avec plus de 100 types de couches de réseaux neuronaux et plus de 20 algorithmes de machine learning traditionnel, permettant de l’adapter à un grand nombre d’utilisations comme la vision par ordinateur et le traitement du langage naturel. La compatibilité de NeoML avec les environnements de différentes plateformes, y compris Windows, Linux, macOS, iOS, et Android, garantit une intégration en toute fluidité aux infrastructures existantes de l’entreprise. De plus, NeoML est compatible avec le format ONNX (Open Neural Network Exchange), ce qui rend possible l’interopérabilité avec d’autres outils de machine learning, et qui renforce son utilité dans divers environnements de programmation via des langages tels que C++, Java, ou Objective C.
Pour les entreprises, NeoML constitue une solution robuste, flexible et rentable pour déployer des modèles de machine learning à travers différents services de l’entreprise. Grâce à sa nature en open-source, validée par une licence Apache 2.0, les entreprises peuvent adapter NeoML à leurs besoins spécifiques sans faire grimper leurs coûts ; elles maximisent ainsi l’efficacité de l’allocation des ressources. Bénéficiant d’un soutien communautaire sans faille, NeoML profite de mises à jour et d’améliorations permanentes. Les entreprises ont ainsi accès à des fonctionnalités de machine learning de pointe. La grande performance de ce cadre, avec assistance CPU et GPU, garantit un traitement rapide des données et des résultats en temps opportun. Cela en fait un choix idéal pour les entreprises qui souhaitent tirer le meilleur parti du machine learning pour innover et gagner en efficacité opérationnelle.

Carlsberg
U.S. FDA
Emerson
Carlsberg accélère la mise sur le marché des boissons
Livraisons
accélérées et satisfaction des clients
>140
heures économisées par mois
92%
de traitement des commandes sans contact

Grâce au traitement intelligent des documents, Carlsberg a transformé numériquement ses processus de commande et de livraison.
La U.S. FDA utilise l’IDP pour protéger la santé publique
>99%
de précision de capture des détails critiques
>120
champs complexes sur deux douzaines de formulaires
30
années d’archives de formulaires transformées

« ABBYY nous a fait entrer dans le XXIe siècle. »

Améliorer le parcours client grâce à la Process Intelligence
Valeur
prête à l'emploi
Améliorations
basées sur les données
Simulation de processus

« La Process Intelligence d’ABBYY nous a aidés à opérer un réel changement culturel : s’appuyer sur les données pour apporter des améliorations. »
- Simon Higgs, Director of Business Transformation
Nous mettons les informations des plus grandes entreprises internationales au travail
+ de 10 000 clients
y compris de nombreuses entreprises du classement Fortune 500 font confiance à ABBYY.
+ de 400 brevets
et demandes de brevet. Un leadership technologique important dans le domaine de l’automatisation intelligente des processus.
+ de 30 ans d’expérience
dans l’offre de solutions d’automatisation intelligente aux entreprises du monde entier.
Nos principes pour une IA digne de confiance
Engagement en faveur d'une science des données responsable
Nous nous engageons à développer des produits rigoureux basés sur les principes de confidentialité, d'exactitude et de sécurité de la science des données, intégrés dans notre portefeuille de produits de traitement intelligent des documents et de Process Intelligence pilotés par l'IA.
Préserver la confidentialité des informations personnelles
Nous intégrons des méthodologies de protection de la vie privée dès la conception qui permettent à nos clients de contrôler et de limiter la collecte et le traitement des informations personnelles.
Garantir l'exactitude et la qualité des produits
Nous adhérons au développement de notre portefeuille de produits pilotés par l'IA qui répond aux normes de l'industrie en matière d'exactitude de l'information.
Conformité aux normes de sécurité de l'industrie
Nous déployons des principes de sécurité « zéro confiance » conçus pour minimiser les risques de cybersécurité.


L'approche d'ABBYY en matière d'IA éthique
IA spécialement conçue pour apporter de la valeur et de l'utilité à l'entreprise
- Nous nous engageons à faire preuve de transparence en ce qui concerne les capacités de nos produits d'IA et à faciliter le feedback de la part des clients.
- Nous nous engageons à mettre en place des cadres de gestion des risques liés à l'IA afin de fournir une approche structurée pour évaluer les risques tout au long du cycle de vie de notre portefeuille de produits alimentés par l'IA
- Nous nous engageons à respecter les réglementations applicables en matière de confidentialité des données et d'IA.
Voir les dernières actualités de l'IA d'ABBYY
ABBYY Marketplace alimente l'intégration des LLM et de la RAG

ABBYY soutient le développement de systèmes d'audit indépendants de l'IA

L’entreprise intelligente

ABBYY Marketplace alimente l'intégration des LLM et de la RAG
ABBYY soutient le développement de systèmes d'audit indépendants de l'IA
L’entreprise intelligente
ABBYY Marketplace alimente l'intégration des LLM et de la RAG
ABBYY soutient le développement de systèmes d'audit indépendants de l'IA
L’entreprise intelligente
Ressources IA d'ABBYY

Rapport
Rapport sur l’état de l’automatisation intelligente : Impact de l'économie sur les priorités en matière d'IA
Rapport
Rapport sur l’état de l’automatisation intelligente : Impact de l'économie sur les priorités en matière d'IA