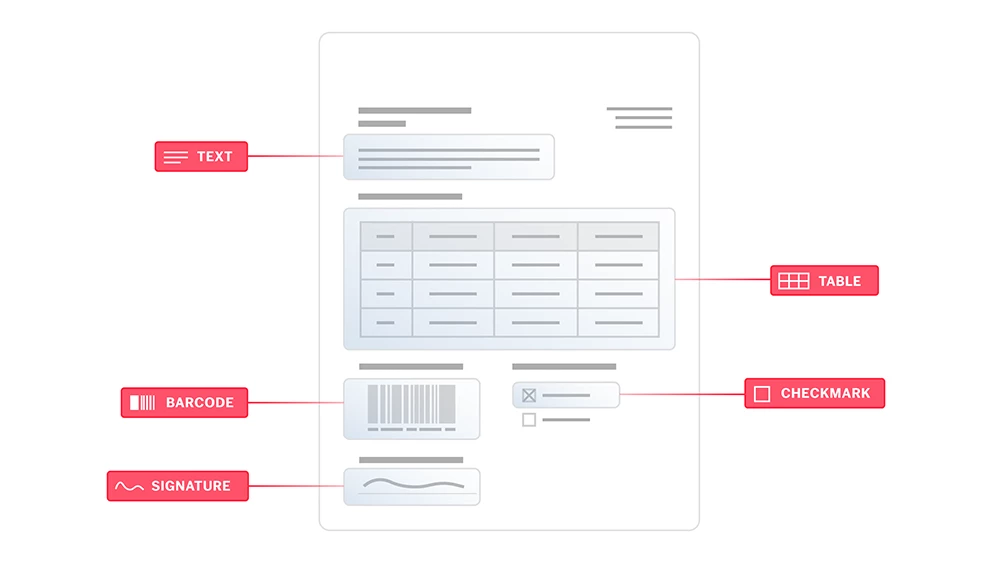
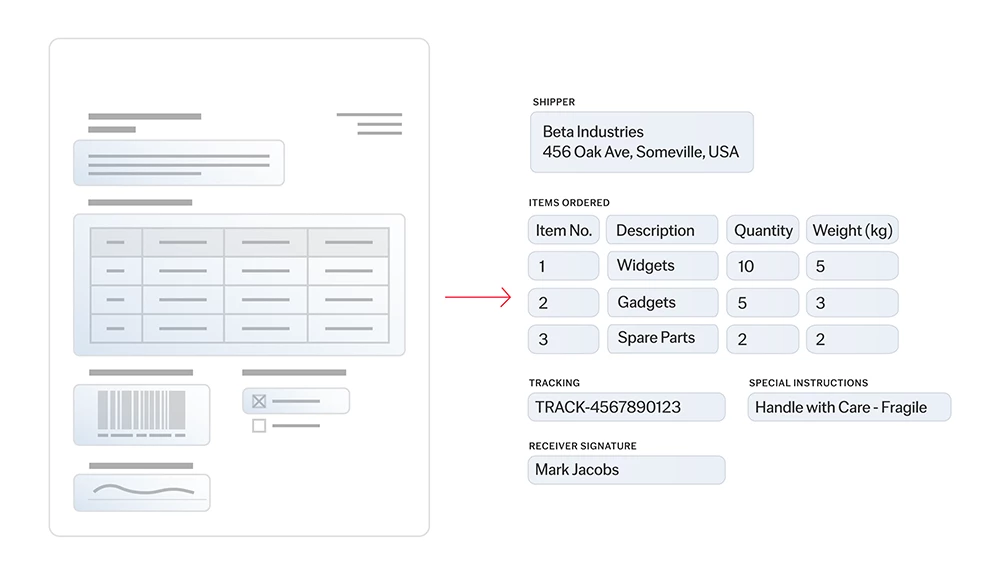
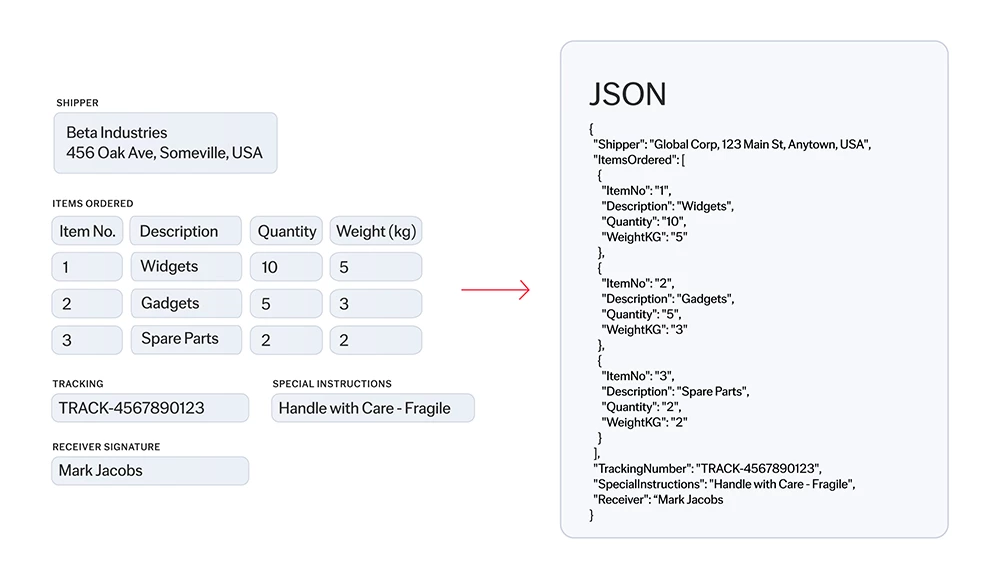
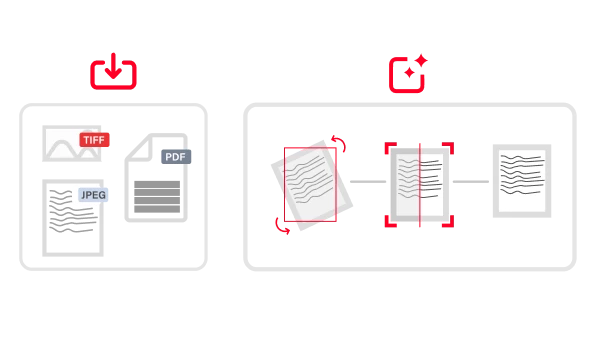
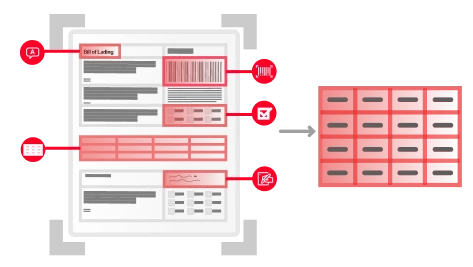
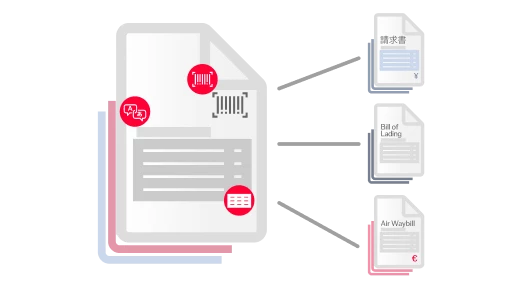
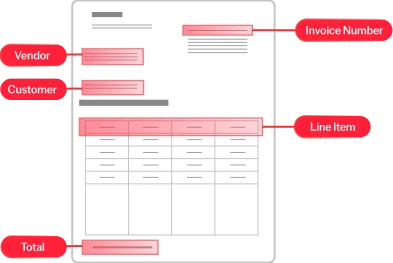
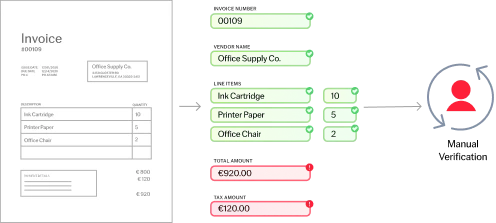
La reconnaissance optique de caractères (OCR) est une technologie conçue pour convertir différents types de documents, comme les documents papier scannés, les PDF ou les images, en données modifiables et interrogeables. Utilisant des algorithmes sophistiqués et le machine learning, l’OCR d’ABBYY identifie et traite les caractères dactylographiés, il comprend la mise en page des documents et leur structure logique, il les convertit en texte structuré lisible par les machines et prêt pour l’IA. Cela permet aux organisations de numériser de gros volumes d’informations initialement sur papier, avec précision et efficacité.
Une OCR précise est une composante essentielle du traitement intelligent des documents, ce qui garantit une extraction précise des données et des résultats fiables qui boostent l’efficacité des entreprises. Une extraction inexacte des données peut entraîner de mauvaises informations, entraver la prise de décision et compromettre les opérations commerciales, ce qui se traduit par un travail manuel accru, des coûts plus élevés et une baisse de productivité. En libérant du contenu et des informations qui étaient « piégés » dans les documents, une OCR précise permet une automatisation fluide et favorise des processus de prise de décision plus intelligents. Cela sert de colonne vertébrale aux flux d’automatisation basés sur l’IA, en transformant des données non structurées en informations exploitables pour des solutions technologiques de pointe.