すべてのブログ記事
帳票処理ソリューション – AI自動学習による文書仕分け・データ抽出
ABBYY Japan エンジニアリングチーム
11月11日, 2020

ABBYY FlexiCapture最大の特長としては「複雑なレイアウトを持つ帳票でもOCRし、データ抽出可能(第1回ブログ)」が挙げられますが、一方で比較的シンプルな帳票については難しい設定無しに文書仕分け・データ抽出が可能です。これを実現可能にした技術が、AI自動学習機能であり、さらにそれを請求書について汎用化した製品が ABBYY FlexiCapture for Invoicesとなります。
「帳票処理ソリューション」シリーズ第3回は、ABBYY FlexiCaptureのAI自動学習機能について紹介いたします。
まず、AI自動学習機能を用いた文書仕分けについてご紹介いたします。
文書仕分けの設定・確認は次の4ステップのみで、非常に簡単に実行可能です。
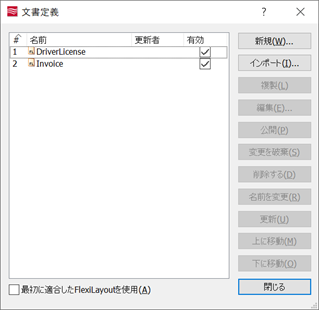
1. 文書定義作成
仕分け結果の格納先となる文書定義名を作成します。
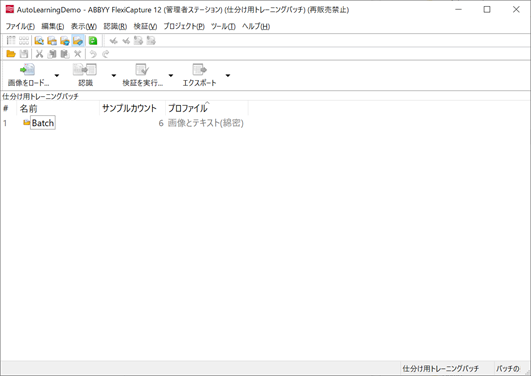
2. 仕分け用トレーニングバッチ作成、学習用画像読み込み
プロジェクト設定ステーションで、仕分け用トレーニングバッチを選択し、新規バッチを作成します。
作成したバッチに、学習用のサンプルイメージを読み込みます。
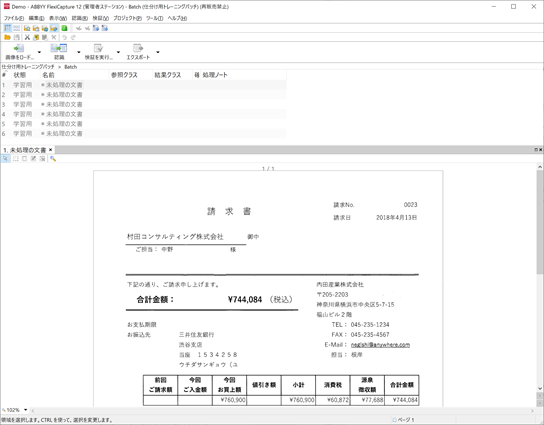
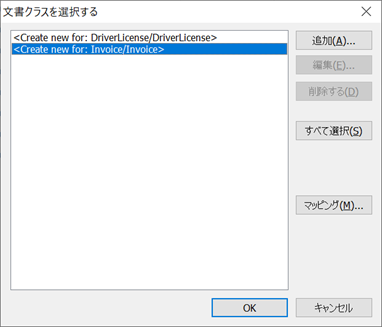
各サンプル画像に対し、仕分けしたいクラス(文書定義)を選択します。
サンプル画像ごとに「学習用」「テスト用」を選択します。
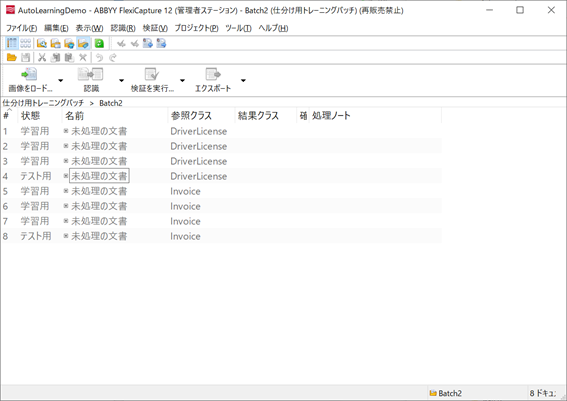
3. 仕分けトレーニング(仕分け学習)とトレーニング結果の設定
ステップ2で仕分けトレーニングの準備が整いましたので、学習ボタンをクリックし、トレーニングを実行、結果を確認します。
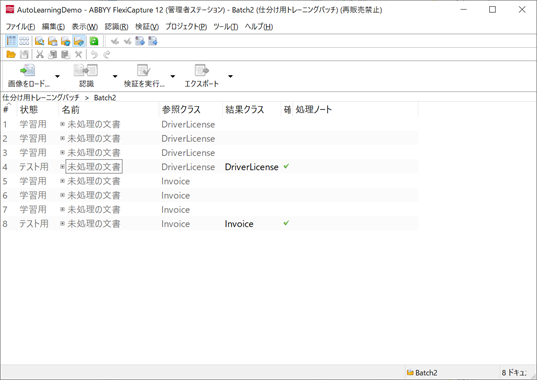
結果に問題なければ、トレーニング結果を認識処理時に適用する設定を実施します。
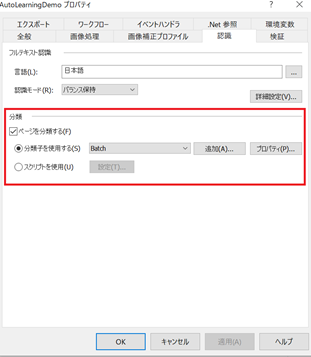
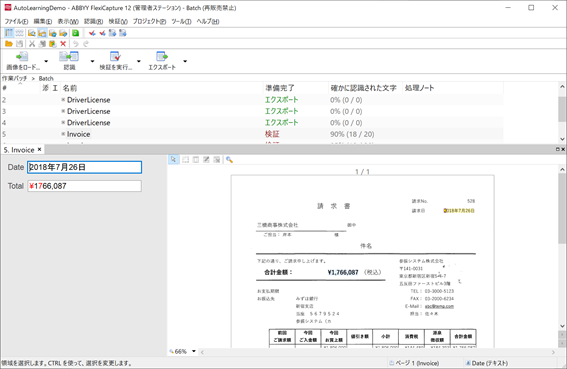
4. 作業バッチで結果を確認
作業バッチでテスト画像を読み込み、正しく仕分けが行われることを確認します。
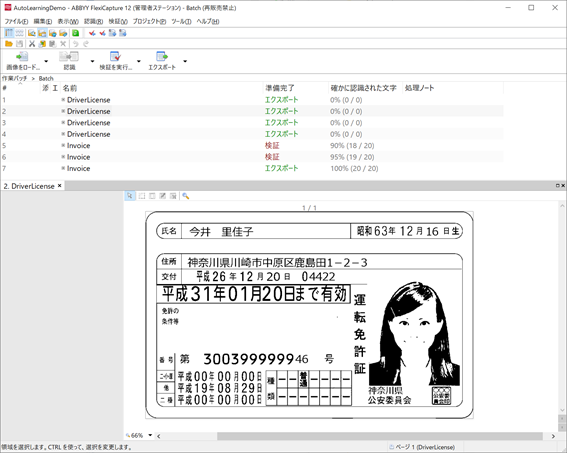
では、次にAI自動学習によるデータ抽出についてご紹介いたします。
データ抽出設定・確認方法は、次の4ステップになります。
※文書仕分けについては既に設定済である事を前提とします。
1. フィールド追加
対象の文書定義にトレーニングしたいフィールドを追加します。
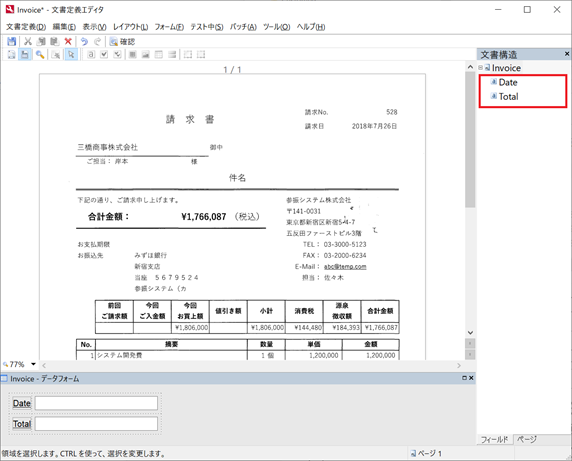
2. データ抽出用トレーニングバッチ作成、学習用画像読み込み
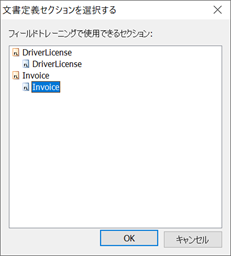
プロジェクト設定ステーションのフィールド抽出用トレーニングバッチで新規バッチを作成します。その際、「文書定義セクションの選択」で該当する文書定義 > セクションを選択します。
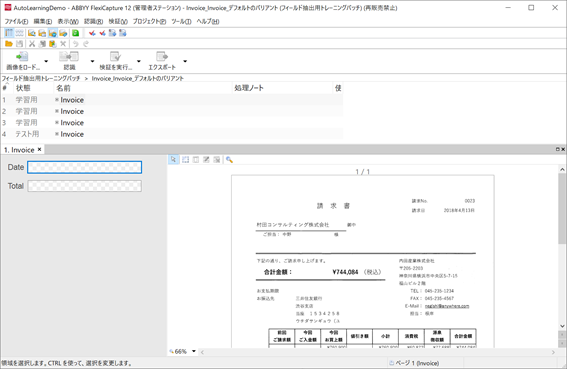
次に、作成したバッチにトレーニング用のサンプル画像ファイルを読み込み、認識を実行します。また、それぞれのサンプル画像に対し「学習用」「テスト用」を設定します。
3. フィールド抽出トレーニングの実施
「学習用」のサンプルドキュメントに対し、各フィールドの正しい位置をクリック、または囲い込みにより指定します。
※ここではフィールドの位置をエンジンに教えているだけですので、文字の修正をする必要はありません。
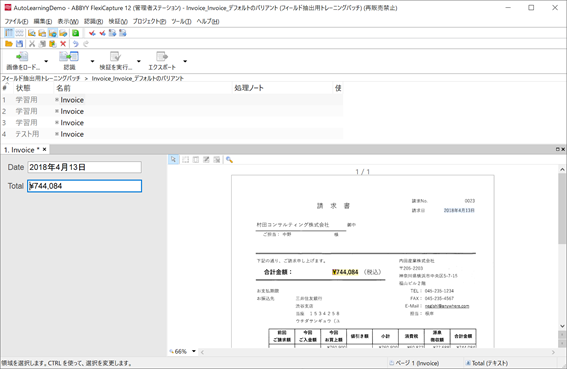
以上でトレーニングの準備が整いましたので、学習ボタンをクリックする事によりトレーニングを実行、トレーニングが完了次第認識処理を実施し、結果を確認します。
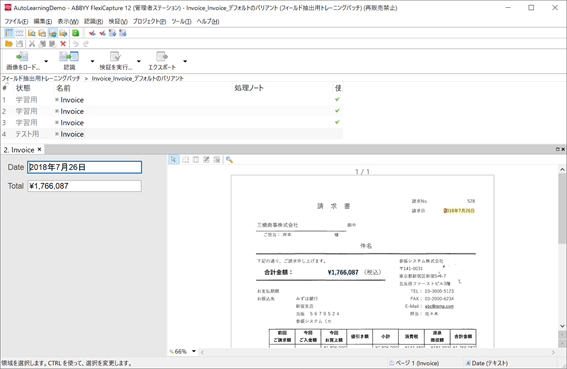
4. 作業バッチで結果を確認
作業バッチでテスト画像を読み込み、正しくフィールド抽出が行われていることを確認します。
いかがでしょうか?
簡単かつ直感的に文書仕分け・データ抽出の設定が可能であることがお分かりいただけたかと思います。
このように、ABBYY FlexiCaptureは、帳票レイアウトの複雑さや取得項目に応じて様々な設定のアプローチをとることが可能です。
ABBYY FlexiCaptureについての概要、デモの依頼、お問い合わせはこちらから承ります。
なお、「帳票処理シリーズ」第一回、第二回はこちらより、アクセス可能です。
また、チュートリアルビデオもこちらより、ご覧頂くことができます。
ABBYY Japan エンジニアリングチーム
ブログの更新を購読する
読み込み中...